Introduction
In the world of data engineering, process logs are the unsung heroes that keep systems running smoothly and help teams troubleshoot issues efficiently
In this article, we’ll explore how to implement effective process logging in the Snowflake cloud data platform.
What is process log?
Process logs are detailed records of events, actions and changes that occur during the execution of workflow (e.g., stored procedures embedded in tasks).
Process logs capture information like timestamps, error messages, source and target tables, and other performance metrics such as the duration, which indicates the time taken to complete a particular task.
Usecases
- Troubleshooting
- Auditing
- Monitoring performance
Structure of the Stored Procedure(SP)
The idea is to create a stored procedure that inserts data into a log table. Then, it becomes easier to call this procedure from any main procedure.
- Create a log table
- Create a SP which inserts the data to table
- Embed the SP_PROCESS_LOG to the main SP
- Calling the main SP and check the PROCESS_LOG table
1. Create a log table
Table Name: PROCESS_LOG
Columns includes:
PROCEDURE_NAME: Name of the Stored Procedures or functions.
SOURCE_TABLE, TARGET_TABLE: The table from which data is loaded and the table to which data is loaded, respectively.
PROCESS_COUNT Total number of rows loaded to the target table.
START_TIMESTAMP, END_TIMESTAMP, PROCESS_DURATION: The time and date when the process started, ended and the total duration of the process.
STATUS, MESSAGE: Status implies whether the task SUCCEEDED/FAILED and the message accordingly.
CREATED_BY, CREATED_AT: The user who executed the procedure and the timestamp of execution. [Note: Column names can be renamed to EXECUTED_BY and EXECUTED_AT.]
Table Definition:
CREATE OR REPLACE TABLE PROCESS_LOG (
PROCEDURE_NAME VARCHAR(16777216),
SOURCE_TABLE VARCHAR(16777216),
TARGET_TABLE VARCHAR(16777216),
PROCESS_COUNT NUMBER(38,0),
START_TIMESTAMP TIMESTAMP_NTZ(9),
END_TIMESTAMP TIMESTAMP_NTZ(9),
STATUS VARCHAR(16777216),
MESSAGE VARCHAR(16777216),
PROCESS_DURATION FLOAT,
WAREHOUSE_NAME VARCHAR(16777216),
CREATED_BY VARCHAR(16777216),
CREATED_AT TIMESTAMP_NTZ(9)
);2. Create a SP which inserts the data to the log table
SP name: SP_PROCESS_LOG Table Name: PROCESS_LOG
SP_PROCESS_LOG takes inputs parameters such as PROCEDURE_NAME ,SOURCE_TABLE ,TARGET_TABLE ,PROCESS_COUNT ,START_TIMESTAMP ,END_TIMESTAMP ,STATUS ,MESSAGE ,PROCESS_DURATION and WAREHOUSE_NAME
This SP is simple, as it only INSERTS data into the PROCESS_LOG table
Points to note are:
- The data types of the input parameters should match the table’s data types. The same applies when embedding the procedure in the main procedure (PROCESS_LOG).
- It’s better to keep
EXECUTE AS CALLERinstead ofOWNER. For more info please check Understanding caller’s rights and owner’s rights - Procedure contains
try, exceptblock
SP Definition
CREATE OR REPLACE PROCEDURE TRANSFORMATION.SP_PROCESS_LOG(
PROCEDURE_NAME VARCHAR(16777216),
SOURCE_TABLE VARCHAR(16777216),
TARGET_TABLE VARCHAR(16777216),
PROCESS_COUNT NUMBER(38,0),
START_TIMESTAMP TIMESTAMP_NTZ(9),
END_TIMESTAMP TIMESTAMP_NTZ(9),
STATUS VARCHAR(16777216),
MESSAGE VARCHAR(16777216),
PROCESS_DURATION FLOAT,
WAREHOUSE_NAME VARCHAR(16777216) DEFAULT NULL
)
RETURNS VARCHAR(16777216)
LANGUAGE PYTHON
RUNTIME_VERSION = '3.9'
PACKAGES = ('snowflake-snowpark-python')
HANDLER = 'sp_process_log'
EXECUTE AS CALLER
AS
$$
def sp_process_log(
snowpark_session,
procedure_name,
source_table,
target_table,
process_count,
start_timestamp,
end_timestamp,
status,
message,
process_duration,
warehouse_name=None
):
try:
# SQL query with parameter placeholders
insert_process_log_sql = '''
INSERT INTO TRANSFORMATION.PROCESS_LOG (
PROCEDURE_NAME,
SOURCE_TABLE,
TARGET_TABLE,
PROCESS_COUNT,
START_TIMESTAMP,
END_TIMESTAMP,
STATUS,
MESSAGE,
PROCESS_DURATION,
WAREHOUSE_NAME,
CREATED_BY,
CREATED_AT
) VALUES (
:1, :2, :3, :4, :5, :6, :7, :8, :9, :10, CURRENT_USER(), CURRENT_TIMESTAMP()
);
'''
# Create a DataFrame with the SQL query and bind parameters
snowpark_session.sql(insert_process_log_sql, params=[
procedure_name,
source_table,
target_table,
process_count,
start_timestamp,
end_timestamp,
status,
message,
process_duration,
warehouse_name
]).collect()
return 'Success'
except Exception as e:
# Return the error message if an exception occurs
return str(e)
$$;3. Embed the SP_PROCESS_LOG to the main SP
After creating SP_PROCESS_LOG embed it within the main SP.
- The main Procedure must contain
try,exceptandfinallyblocks. - Declare the necessary parameters in all three blocks (i.e.,
try,except, andfinally) to ensure all metrics are captured.- Parameters are :
current_user,current_wh,process_start_time,processed_row_count,process_status,error_message - Ensure all parameters have the required values and correct data types.
- Parameters are :
- Call the procedure in the
finallyblock
Example:
CREATE OR REPLACE PROCEDURE SP_CUSTOMER()
RETURNS STRING
LANGUAGE PYTHON
RUNTIME_VERSION = '3.9'
PACKAGES = ('snowflake-snowpark-python')
HANDLER = 'SP_CUSTOMER'
AS
$$
def SP_CUSTOMER(snowpark_session):
# Fetch current user and start time
current_user = snowpark_session.sql('SELECT CURRENT_USER()').collect()[0][0]
current_wh = snowpark_session.sql('SELECT CURRENT_WAREHOUSE()').collect()[0][0]
process_start_time = snowpark_session.sql('SELECT CURRENT_TIMESTAMP()').collect()[0][0]
processed_row_count = None
process_status = "SUCCESS"
error_message = None
try:
# Merge statement to update or insert customer data
merge_customer_sql = '''
MERGE INTO transformation.customer c
USING (
SELECT
customer_id,
name,
email,
phone,
address,
CASE
WHEN phone LIKE '123-%' THEN 'USA'
WHEN phone LIKE '44-%' THEN 'UK'
ELSE 'Unknown'
END AS country_code
FROM raw.raw_customer
) rc
ON c.customer_id = rc.customer_id
WHEN MATCHED THEN
UPDATE SET
c.name = rc.name,
c.email = rc.email,
c.phone = rc.phone,
c.address = rc.address,
c.country_code = rc.country_code
WHEN NOT MATCHED THEN
INSERT (customer_id, name, email, phone, address, country_code)
VALUES (
rc.customer_id,
rc.name,
rc.email,
rc.phone,
rc.address,
rc.country_code
);
'''
# Execute the merge statement
merge_result = snowpark_session.sql(merge_customer_sql).collect()
processed_row_count = merge_result[0]['number of rows updated'] + merge_result[0]['number of rows inserted']
except Exception as e:
# Handle exceptions and log failure
process_status = "FAILURE"
error_message = str(e).replace("'", " ") # Sanitize error message for SQL
processed_row_count = None
finally:
# Calculate process duration
process_end_time = snowpark_session.sql('SELECT CURRENT_TIMESTAMP()').collect()[0][0]
process_duration_seconds = snowpark_session.sql(f'''
SELECT DATEDIFF(second, '{process_start_time}', '{process_end_time}')
''').collect()[0][0]
status = 'Customer data loaded sucessfully!'
# Log the process details
log_process_sql = f'''
CALL TRANSFORMATION.SP_PROCESS_LOG(
'SP_CUSTOMER', -- PROCEDURE_NAME (VARCHAR)
'raw.raw_customer', -- SOURCE_TABLE (VARCHAR)
'transformation.customer', -- TARGET_TABLE (VARCHAR)
{processed_row_count if processed_row_count is not None else '0'}, -- PROCESS_COUNT (NUMBER)
'{process_start_time}'::TIMESTAMP_NTZ, -- START_TIMESTAMP (TIMESTAMP_NTZ)
'{process_end_time}'::TIMESTAMP_NTZ, -- END_TIMESTAMP (TIMESTAMP_NTZ)
'{process_status}', -- STATUS (VARCHAR)
{f"'Customer data loaded sucessfully!'" if error_message is None else f"'{error_message}'"}, -- MESSAGE (VARCHAR)
{process_duration_seconds}, -- PROCESS_DURATION (FLOAT)
'{current_wh}'
);
'''
snowpark_session.sql(log_process_sql).collect()
return process_status
$$;4. Calling the main SP and check the PROCESS_LOG table
I’ve created a table to load the data from RAW to TRANSFORMATION layer
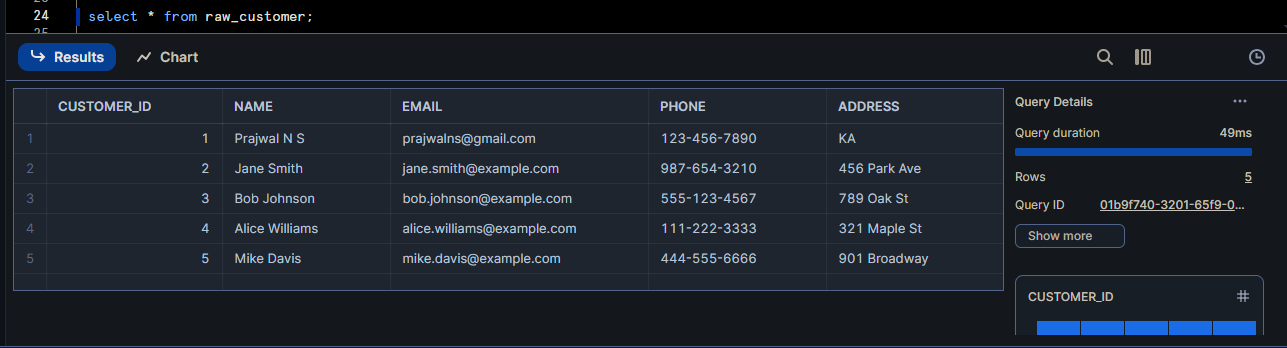
Customer table data (RAW layer)
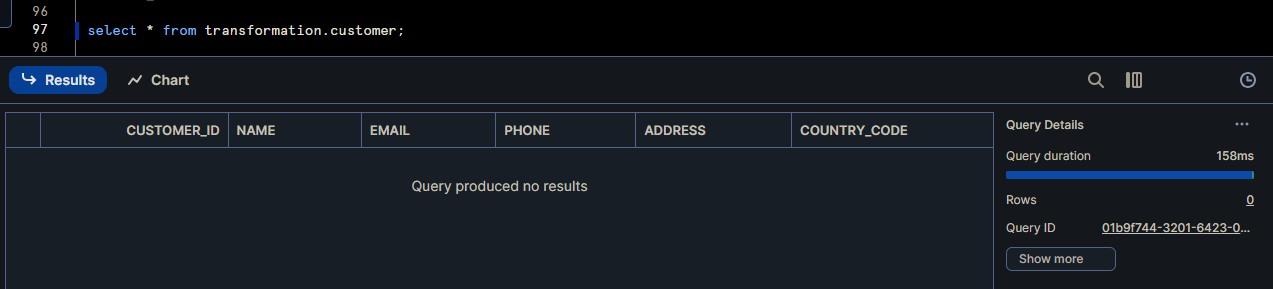
Customer table data (TRANSFORMATION layer)
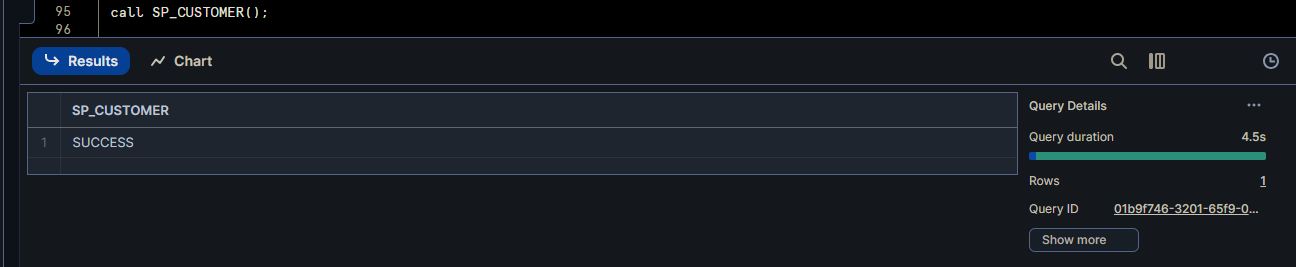
Running the main procedure
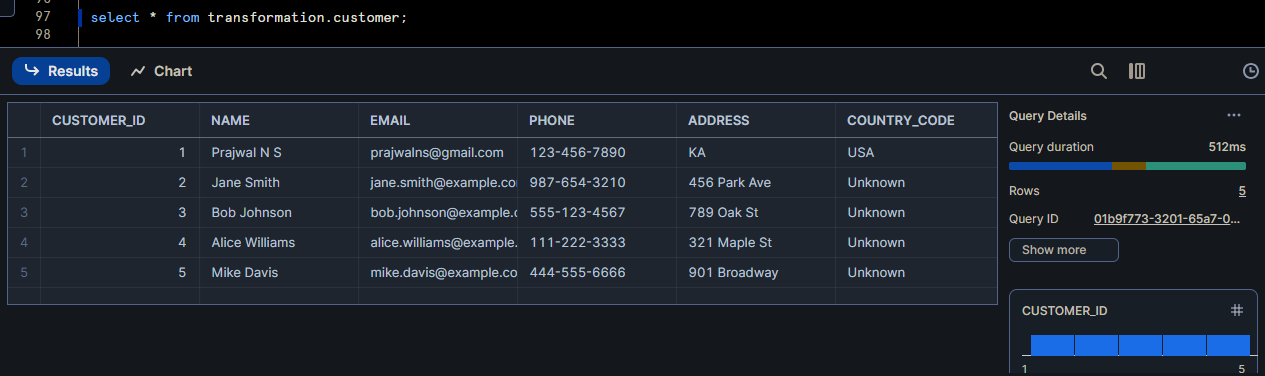
Customer table data (TRANSFOMATION layer)
PROCESS_LOG

Testing for error and the result in PROCESS_LOG
| PROCEDURE_NAME | SOURCE_TABLE | TARGET_TABLE | PROCESS_COUNT | START_TIMESTAMP | END_TIMESTAMP | STATUS | MESSA | PROCESS_DURATION | WAREHOUSE_NAME | CREATED_BY | CREATED_AT |
| SP_CUSTOMER | raw.raw_customer | transformation.customer | 5 | 2025-01-26 01:39:07.799 | 2025-01-26 01:39:08.277 | SUCCESS | Customer data loaded sucessful | 1 | SANDBOX_WH | PRAJWALNS777 | 2025-01-26 01:39:10.039 |
| SP_CUSTOMER | raw.raw_customer | transformation.customer | 0 | 2025-01-26 01:39:39.387 | 2025-01-26 01:39:39.681 | FAILU String Prajwal N S is too long and would be truncated ated | 0 | SANDBOX_WH | PRAJWALNS777 | 2025-01-26 01:39:41.457 |

Conclusion
Obviously, additional columns can be added for logging (e.g., UPDATED and INSERTED counts), but this is the standard template I use.
Also, if you’re wondering why not use Snowflake’s Event Table, it can indeed be implemented. However, personally, I find it less flexible and customizable to my liking. While there’s a workaround by creating views on top of the Event Table, it still feels like a completely different task.
Lastly, I think it’s pretty cool to write your own logging framework rather than relying on the Event Table. Chill! I’m not re-inventing the wheel or something:)
Any kind of feedbacks are welcome!